Introduction
Linked lists are an important data structure used in programming. They are especially useful when the size of the data is unknown and dynamic, or when we want to implement other data structures like stacks and queues. In this tutorial, we’ll focus on singly linked lists (SLL), one of the most commonly used linked list implementations.
Read the following tutorial, to learn about Doubly Linked List.
What is a Singly Linked List?
A singly linked list is a linked list where each node contains a data element and a pointer to the next node in the list. The first node is called the head and the last node points to NULL, indicating the end of the list.
Representation of SLL
A singly linked list is a data structure that consists of a sequence of nodes where each node stores a data value and a pointer to the next node in the sequence. The first node in the list is called the head node, and the last node is called the tail node.
Here’s an illustration of a singly linked list: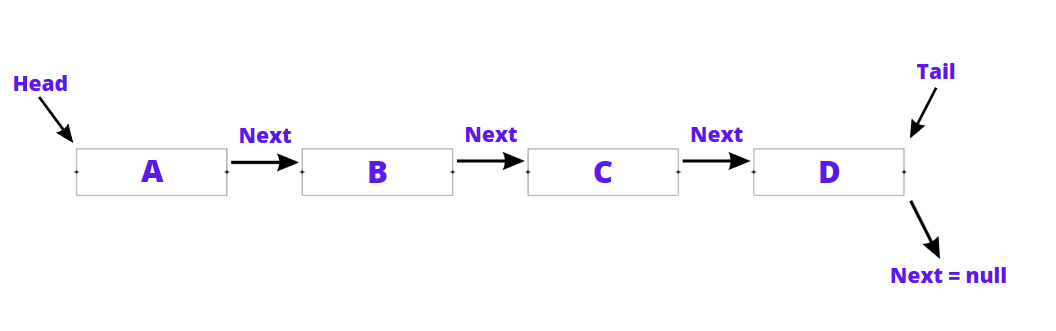
In this example, we have a singly linked list with four nodes, each containing a data value and a pointer to the next node. The head pointer points to the first node, and the tail pointer points to the last node. The next pointer of the last node is set to null, indicating the end of the list.
Implementation of the Node class for a Singly linked list in Java
public class Node {
String data; // The data stored in the node
Node next; // A reference to the next node in the list
// Constructor to create a new node with the specified data
public Node(String data) {
this.data = data;
this.next = null; // By default, a new node has no next node
}
}
The Node class has two instance variables: data and next. data is a string that represents the data stored in the node. next is a reference to the next node in the list.
The Node constructor takes a string value as an argument, sets the data field to that value, and initializes next to null. This implementation can be used to construct a Singly Linked List by creating multiple instances of the Node class and linking them together using the next reference like we will do in the following example:
public class SinglyLinkedListExample {
public static class Node {
String data; // The data stored in the node
Node next; // A reference to the next node in the list
// Constructor to create a new node with the specified data
public Node(String data) {
this.data = data;
this.next = null; // By default, a new node has no next node
}
}
public static void main(String[] args) {
// create the nodes for the linked list
Node canada = new Node("Canada");
Node usa = new Node("United States");
Node mexico = new Node("Mexico");
Node brazil = new Node("Brazil");
Node france = new Node("France");
// link the nodes together to form a singly linked list
canada.next = usa;
usa.next = mexico;
mexico.next = brazil;
brazil.next = france;
// traverse the linked list and print out each node's data
Node current = canada;
while (current != null) {
System.out.println(current.data);
current = current.next;
}
}
}
Output:
Canada United States Mexico Brazil France
This code creates a SinglyLinkedListExample class with a Node sub-class that defines a simple node for a singly linked list. The main method creates several Node objects with country names, links them together to form a singly linked list, and then traverses the linked list to print out the country names.
Advantages of SLL over other data structures
Singly Linked Lists have a few advantages over other data structures, including:
1. Dynamic size
Singly Linked Lists are a dynamic data structure, which means that they can change in size as needed. This is in contrast to static data structures, such as arrays, which have a fixed size that is determined at the time of creation. With a Singly Linked List, you can add or remove nodes from the list as needed, without having to worry about running out of space or exceeding the maximum size of the list.
Dynamic sizing is especially useful when you don’t know in advance how many elements you will need to store. For example, if you’re writing a program that reads a file of unknown length, you can use a Singly Linked List to store the contents of the file as you read it, without having to allocate a fixed amount of memory in advance. Similarly, in a program that receives user input, you can use a Singly Linked List to store the input as it comes in, without having to worry about the maximum length of the input.
Overall, the dynamic sizing of Singly Linked Lists makes them more flexible and adaptable than static data structures like arrays. This is one of the key advantages of Singly Linked Lists and is one reason why they are widely used in many programming applications.
2. Efficient insertion and deletion
One of the primary benefits of Singly Linked Lists is their ability to efficiently insert or delete a node at any position in the list. This is because Singly Linked Lists use pointers to link the nodes together, rather than storing them in contiguous blocks of memory like arrays. When you insert or delete a node in a Singly Linked List, you only need to update a few pointers to re-establish the connections between the neighboring nodes. This is in contrast to an array, where you may need to shift all the elements that come after the insertion or deletion point, which can be time-consuming and inefficient.
Efficient insertion and deletion make Singly Linked Lists a great choice for applications where you need to add or remove elements from the middle of the list, such as sorting or searching algorithms. It also makes them a good choice for implementing data structures like stacks and queues, where you frequently need to add or remove elements from the beginning or end of the list.
Overall, the efficient insertion and deletion of Singly Linked Lists is a significant advantage over other data structures, especially in situations where you need to add or remove elements frequently.
3. Easy implementation
Singly Linked Lists have a straightforward implementation that involves creating a node structure and using pointers to connect the nodes. This simplicity makes them a popular choice for teaching data structures and algorithms, as well as for quickly prototyping code.
Because Singly Linked Lists are easy to implement, they can be a good starting point for learning about more complex data structures, such as doubly linked lists or trees. The basic principles used to implement Singly Linked Lists are also applicable to other data structures, such as stacks and queues, which are frequently used in programming applications.
The ease of implementation also makes Singly Linked Lists a good choice when you need a simple data structure for storing and manipulating data. If you have a small amount of data to manage, or you need a data structure that can be easily modified or extended, a Singly Linked List can be an excellent option.
Overall, the easy implementation of Singly Linked Lists makes them a great choice for both learning and practical programming applications. Their simplicity and flexibility make them an attractive option for programmers of all skill levels.
Disadvantages of SLL and when it is not ideal to use
1. No constant-time access to nodes
One of the main disadvantages of Singly Linked Lists is that they do not provide constant-time access to nodes at arbitrary positions in the list. This means that if you want to access a node at a specific index or position in the list, you have to traverse the list from the beginning until you reach the desired node. This traversal can be inefficient for large lists, since it requires O(n) time complexity where n is the number of nodes in the list.
In contrast, arrays and other indexed data structures can provide constant-time access to nodes at arbitrary positions, since the location of each node in the array can be computed directly from its index. This makes arrays more efficient for use cases where you need to access nodes at specific positions in the list frequently.
It’s important to choose the data structure that is most appropriate for the specific use case, taking into account factors such as the frequency and types of operations performed on the data structure, the size of the data set, and the available memory resources.
2. Extra memory overhead
Singly Linked Lists require an additional pointer (or reference) to be stored in each node to point to the next node in the list. This can add significant memory overhead, especially if the data being stored in each node is relatively small. In contrast, arrays only require a single contiguous block of memory, and other data structures like stacks and queues can be implemented with smaller overhead.
The memory overhead of Singly Linked Lists can be especially significant for large lists, where the additional pointers can consume a substantial portion of the available memory. Additionally, Singly Linked Lists can be less cache-friendly than arrays and other data structures, since the nodes may be scattered throughout memory rather than stored in a contiguous block.
As with any data structure, it’s important to consider the trade-offs and choose the structure that is most appropriate for the specific use case.
3. Cannot be traversed in reverse
Singly Linked Lists are designed to be traversed in a forward direction from the head of the list to the tail. This is because each node only has a reference to the next node in the list, not the previous node. This means that if you want to traverse the list in reverse, you have to start from the tail of the list and move backwards to the head, which is not efficient.
To traverse a Singly Linked List in reverse, you need to use additional data structures, such as a stack or another linked list, to store the nodes as you traverse the list forward. Once you reach the end of the list, you can then pop the nodes from the stack or traverse the second list backwards to traverse the original list in reverse. This additional overhead can make operations on Singly Linked Lists more complex and less efficient than on other data structures that can be traversed in reverse more easily, such as Doubly Linked Lists or Arrays.
Overall, the inability to traverse Singly Linked Lists in reverse without additional overhead can be a significant disadvantage for use cases that require frequent reverse traversal. It’s important to carefully consider the requirements of your specific use case when choosing a data structure.
Operations on singly linked list
1. Insertion: Adding a node at the beginning of the list
The insertAtBeginning method takes two parameters: the head of the list, which is a reference to the first node in the list, and the data to be stored in the new node. It creates a new Node object with the given data, sets its next reference to the current head, and updates the head parameter to point to the new node. This effectively inserts the new node at the beginning of the list. The method then returns the updated head reference as the new head of the list.
//Inserts a new node containing the given data at the beginning of the list.
public static Node insertAtBeginning(Node head, String data) {
Node newNode = new Node(data); // create a new node with the given data
newNode.next = head; // set the new node's next reference to the current head
head = newNode; // update the head of the list to point to the new node
return head; // return the new head of the list
}
Let’s proceed with implementing the method and observing its practical functionality in action:
public class SinglyLinkedListExample {
public static void main(String[] args) {
// create the nodes for the linked list
Node canada = new Node("Canada");
Node usa = new Node("United States");
Node mexico = new Node("Mexico");
// link the nodes together to form a singly linked list
canada.next = usa;
usa.next = mexico;
// insert a new node at the beginning of the list
Node newHead = insertAtBeginning(canada, "Brazil");
// print the data of the nodes in the linked list
Node current = newHead;
while (current != null) {
System.out.println(current.data);
current = current.next;
}
}
public static Node insertAtBeginning(Node head, String data) {
Node newNode = new Node(data); // create a new node with the given data
newNode.next = head; // set the new node's next reference to the current head
head = newNode; // update the head of the list to point to the new node
return head; // return the new head of the list
}
public static class Node {
// The data that the node holds.
String data;
// A reference to the next node in the linked list.
Node next;
public Node(String data) {
this.data = data;
}
}
}
Output:
Brazil Canada United States Mexico
This program creates a singly linked list with three nodes representing Canada, the United States, and Mexico. It then calls the insertAtBeginning method to add a new node containing the data “Brazil” to the beginning of the list. The program then iterates over the list and prints the data of each node in the list.
2. Deletion: Removing a node from the list
Deleting a node from a singly linked list involves updating the next reference of the previous node to skip over the node to be deleted, effectively removing it from the list. The process for deleting a node depends on the position of the node to be deleted in the list.
Deleting the first node
To delete the first node of a singly linked list, we simply update the head reference to point to the second node in the list, effectively removing the first node.
public Node deleteFirstNode(Node head) {
if (head == null) {
// list is already empty
return null;
}
// update the head to the next node in the list
head = head.next;
return head;
}
Now, we’ll implement the method and see how it practically works in our code:
public class SinglyLinkedListExample {
public static void main(String[] args) {
// create the nodes for the linked list
Node canada = new Node("Canada");
Node usa = new Node("United States");
Node mexico = new Node("Mexico");
Node brazil = new Node("Brazil");
Node france = new Node("France");
// link the nodes together to form a singly linked list
canada.next = usa;
usa.next = mexico;
mexico.next = brazil;
brazil.next = france;
// delete the first node in the linked list
canada = deleteFirstNode(canada);
// print out the remaining nodes in the linked list
Node current = canada;
while (current != null) {
System.out.println(current.data);
current = current.next;
}
}
public static Node deleteFirstNode(Node head) {
if (head == null) {
// list is already empty
return null;
}
// update the head to the next node in the list
head = head.next;
return head;
}
public static class Node {
// The data that the node holds.
String data;
// A reference to the next node in the linked list.
Node next;
public Node(String data) {
this.data = data;
}
}
}
Output:
United States Mexico Brazil France
In this code, we create a singly linked list of country names, with each node represented by the Node class. We then define a deleteFirstNode method which deletes the first node of the linked list and returns the new head of the list. Finally, in the main method, we demonstrate the use of the deleteFirstNode method by calling it on the head of the linked list and printing out the remaining nodes in the list.
Deleting a node in the middle of the list
To delete a node in the middle of a singly linked list, we need to find the previous node and update its next reference to skip over the node to be deleted.
public Node deleteNode(Node head, String key) {
Node current = head;
Node previous = null;
while (current != null && current.data != key) {
previous = current;
current = current.next;
}
if (current == null) {
// node with the given key not found
return head;
}
if (previous == null) {
// the node to be deleted is the first node
head = current.next;
} else {
// update the previous node's next reference to skip over the current node
previous.next = current.next;
}
return head;
}
Implementing the deleteNode method and using it is shown below:
public class SinglyLinkedListExample {
public static void main(String[] args) {
// create the nodes for the linked list
Node canada = new Node("Canada");
Node usa = new Node("United States");
Node mexico = new Node("Mexico");
Node brazil = new Node("Brazil");
Node france = new Node("France");
// link the nodes together to form a singly linked list
canada.next = usa;
usa.next = mexico;
mexico.next = brazil;
brazil.next = france;
// delete a node from the linked list
canada = deleteNode(canada, "Mexico");
// print the linked list
Node current = canada;
while (current != null) {
System.out.println(current.data);
current = current.next;
}
}
public static Node deleteNode(Node head, String key) {
Node current = head;
Node previous = null;
while (current != null && !current.data.equals(key)) {
previous = current;
current = current.next;
}
if (current == null) {
// node with the given key not found
return head;
}
if (previous == null) {
// the node to be deleted is the first node
head = current.next;
} else {
// update the previous node's next reference to skip over the current node
previous.next = current.next;
}
return head;
}
public static class Node {
// The data that the node holds.
String data;
// A reference to the next node in the linked list.
Node next;
public Node(String data) {
this.data = data;
}
}
}
This program demonstrates the use of the deleteNode method in a singly linked list. The deleteNode method takes a head node and a key as arguments, and searches the linked list for a node with the given key. If a node with the given key is found, it is removed from the linked list. If the node to be deleted is the first node, the head reference is updated to point to the second node in the list. If the node to be deleted is not the first node, the next reference of the previous node is updated to skip over the node to be deleted. The main method creates a singly linked list of country nodes, deletes the node with the country name “Mexico”, and then prints the remaining nodes in the linked list.
3. Traversal: visiting each node in the list
Traversal is an essential operation on a linked list, as it involves visiting each node in the list and performing some operation on it. In Singly Linked Lists, this involves starting at the head of the list and traversing the list by following the next pointers until the end of the list is reached.
public void traverse(Node head) {
Node current = head;
while (current != null) {
// Perform some operation on the current node
System.out.print(current.data + " ");
// Move to the next node in the list
current = current.next;
}
System.out.println();
}
The following code demonstrates the implementation of the Node class and its usage:
public class SinglyLinkedListExample {
public static class Node {
// The data that the node holds.
String data;
// A reference to the next node in the linked list.
Node next;
public Node(String data) {
this.data = data;
}
}
public static void traverse(Node head) {
Node current = head;
while (current != null) {
// Perform some operation on the current node
System.out.print(current.data + " ");
// Move to the next node in the list
current = current.next;
}
System.out.println();
}
public static void main(String[] args) {
// create the nodes for the linked list
Node canada = new Node("Canada");
Node usa = new Node("United States");
Node mexico = new Node("Mexico");
Node brazil = new Node("Brazil");
Node france = new Node("France");
// link the nodes together to form a singly linked list
canada.next = usa;
usa.next = mexico;
mexico.next = brazil;
brazil.next = france;
// traverse the linked list
traverse(canada);
}
}
Output:
Canada United States Mexico Brazil France
In this implementation, the SinglyLinkedListExample class has a Node subclass that has a data field to hold the node’s data and a next field that points to the next node in the list. The traverse method takes the head of the linked list as an argument, and iterates through the list, performing some operation on each node (in this case, printing the node’s data to the console). The main method creates a linked list of world countries and calls the traverse method to print out the countries in the list.
4. Searching: finding a specific node in the list
Searching is the process of finding a specific node in the list. The search can be done by comparing the data of each node in the list to the data being searched. If the data is found, the node is returned; otherwise, the search continues until the end of the list is reached.
public Node findNode(Node start, String data) {
Node current = start;
while (current != null) {
if (current.data.equals(data)) {
return current; // return the node if found
}
current = current.next; // move to the next node
}
return null; // return null if the node is not found
}
Let’s implement the method and see how it practically works in our code:
public class SinglyLinkedListExample {
public static void main(String[] args) {
// create the nodes for the linked list
Node canada = new Node("Canada");
Node usa = new Node("United States");
Node mexico = new Node("Mexico");
Node brazil = new Node("Brazil");
Node france = new Node("France");
// link the nodes together to form a singly linked list
canada.next = usa;
usa.next = mexico;
mexico.next = brazil;
brazil.next = france;
// find a node in the linked list
Node result = findNode(canada, "Brazil");
if (result != null) {
System.out.println("Node found: " + result.data);
} else {
System.out.println("Node not found.");
}
}
public static Node findNode(Node start, String data) {
Node current = start;
while (current != null) {
if (current.data.equals(data)) {
return current; // return the node if found
}
current = current.next; // move to the next node
}
return null; // return null if the node is not found
}
public static class Node {
// The data that the node holds.
String data;
// A reference to the next node in the linked list.
Node next;
public Node(String data) {
this.data = data;
}
}
}
Output:
Node found: Brazil
In the main method, the code creates a singly linked list of country nodes, and then calls the findNode method to search for a node with the string “Brazil”. If the node is found, the code prints out a message saying that the node was found and its data. If the node is not found, the code prints out a message saying that the node was not found.
The findNode() method takes two parameters: the head of the list, which is a reference to the first node in the list, and the data to be searched. It traverses the list until the node with the desired data is found or the end of the list is reached.
In the while loop, we check if the current node’s data is equal to the data being searched. If it is, we return the current node. If it is not, we move to the next node by updating the current reference to the next node in the list.
If the end of the list is reached without finding the node, we return null to indicate that the node was not found.
Applications of singly linked list
1. Implementing other data structures like stacks and queues
Singly Linked Lists are commonly used to implement other data structures such as stacks and queues. A stack is a data structure that follows the Last-In-First-Out (LIFO) principle, which means that the last element added to the stack is the first one to be removed. In a singly linked list implementation of a stack, new elements are added at the head of the list, and removed elements are also taken from the head of the list.
Similarly, a queue is a data structure that follows the First-In-First-Out (FIFO) principle, which means that the first element added to the queue is the first one to be removed. In a singly linked list implementation of a queue, new elements are added at the tail of the list, and removed elements are taken from the head of the list.
The advantage of using a singly linked list to implement these data structures is that the operations of adding or removing elements can be done in constant time, regardless of the size of the list. This is because adding or removing an element in a singly linked list only requires updating the head or tail of the list, respectively, and does not require moving any other elements in the list.
2. Managing memory allocation in operating systems
Singly linked lists can also be used to manage memory allocation in operating systems. In operating systems, memory allocation is a process of assigning a block of memory to a process or program for its use. A singly linked list can be used to keep track of the available memory blocks and allocated memory blocks. The list can be organized in such a way that the allocated memory blocks are linked to each other, while the free memory blocks are also linked to each other. The beginning of the list contains the first available memory block.
When a program requests a block of memory, the operating system can traverse the list to find the first available block of the required size, allocate it to the program, and update the list accordingly. When the program finishes using the memory block, it can be deallocated and added back to the free memory blocks list.
Using singly linked lists for memory allocation in operating systems can improve the efficiency of memory management by reducing fragmentation and allowing for faster memory allocation and deallocation.
3. Polynomial arithmetic
Singly linked lists can be used to implement graph algorithms like Depth First Search (DFS) and Breadth First Search (BFS). In these algorithms, the graph is represented as a collection of linked lists, where each node in the list represents a vertex and each edge is represented by a pointer to the next node in the list. The advantage of using linked lists is that the edges can be easily added or removed as the algorithm progresses, without having to restructure the entire graph. This makes graph algorithms efficient and easy to implement using SLL.
For example, in the case of DFS, a stack is used to keep track of the visited nodes. To perform the search, we push the starting node onto the stack and then repeatedly remove the top node from the stack, mark it as visited, and push its unvisited neighbors onto the stack. Using a singly linked list to represent the graph, the unvisited neighbors can be easily obtained by following the edges in the linked list. Similarly, for BFS, a queue is used to keep track of the visited nodes, and the unvisited neighbors can be obtained by following the edges in the linked list.
Overall, SLLs provide a simple and efficient way to represent graphs, which are a fundamental data structure in computer science and have a wide range of applications in various fields.
Conclusion
In conclusion, a singly linked list is a powerful and versatile data structure that has many useful applications in computer science. It allows for efficient insertion and deletion of elements and can be used to implement other more complex data structures like stacks and queues. While it has some limitations, like not being able to traverse in reverse, these drawbacks are often outweighed by the benefits of using a linked list. By understanding the basic operations and applications of a singly linked list, you can greatly expand your programming toolkit and become a more effective developer.